
High Availability – Introduction to Serverless on AWS
High Availability
A highly available (HA) application avoids a single point of failure by adding redun‐ dancy. For a commercial application, the service level agreement (SLA) states the availability in terms of a percentage. In serverless, as we employ fully managed
services, AWS takes care of the redundancy and data replication by distributing the compute and storage resources across multiple AZs, thus avoiding a single point of failure. Hence, adopting serverless provides high availability out of the box as standard.
Cold Start
Cold start is commonly associated with FaaS. For example, as you saw earlier, when an AWS Lambda function is idle for a period of time its execution environment is shut down. If the function gets invoked again after being idle for a while, AWS provisions a new execution environment to run it. The latency in this initial setup is usually called the cold start time. Once the function execution is completed, the Lambda service retains the execution environment for a nondeterministic period. If the function is invoked again during this period, it does not incur the cold start latency. However, if there are additional simultaneous invocations, the Lambda service provisions a new execution environment for each concurrent invocation, resulting in a cold start.
Many factors contribute to this initial latency: the size of the function’s deployment package, the runtime environment of the programming language, the memory (RAM) allocated to the function, the number of preconfigurations (such as static data initializations), etc. As an engineer working in serverless, it is essential to under‐ stand cold start as it influences your architectural, developmental, and operational decisions (see Figure 1-9).
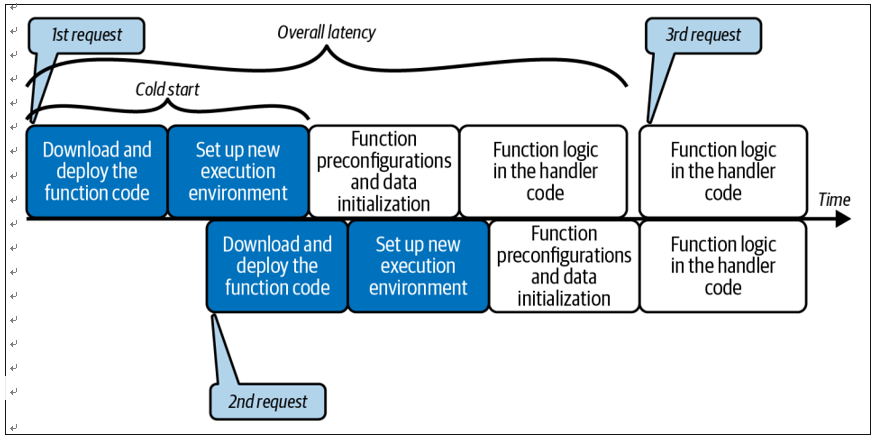
Figure 1-9. Function invocation latency for cold starts and warm executions—requests 1 and 2 incur a cold start, whereas a warm container handles request 3