Modern cloud applications ingest huge volumes of data—operational data, metrics, logs, etc. Teams that own the data might want to optimize their storage (to mini‐ mize cost and, in some cases, improve performance) by isolating and keeping only business-critical data.
Managed data services provide built-in features to remove or transition unneeded data. For example, Amazon S3 supports per-bucket data retention policies to either delete data or transition it to a different storage class, and DynamoDB allows you to configure the Time to Live (TTL) value on every item in a table. The storage optimization options are not confined to the mainstream data stores; you can specify the message retention period for each SQS queue, Kinesis stream, API cache, etc.
DynamoDB manages the TTL configuration of the table items efficiently, regardless of how many items are in a table and how many of those items have a TTL timestamp set. However, in some cases, it can take up to 48 hours for an item to be deleted from the table. Consequently, this may not be an ideal solution if you require guaranteed item removal at the exact TTL time.
AWS Identity and Access Management (IAM)
AWS IAM is a service that controls the authentication and authorization of access to AWS services and resources. It helps define who can access which services and resources, under which conditions. Access to a service or resource can be granted to an identity, such as a user, or a resource, such as a Lambda function. The object that holds the details of the permissions is known as a policy and is stored as a JSON document, as shown in Example 1-1.
Example 1-1. IAM policy to allow read actions on DynamoDB Orders table
Support for Deeper Security and Data Privacy Measures
You now understand how the individuality and granularity of services in serverless enable you to fine-tune every part of an application for varying demands. The same characteristics allow you to apply protective measures at a deeper level as necessary across the ecosystem.
Permissions at a function level
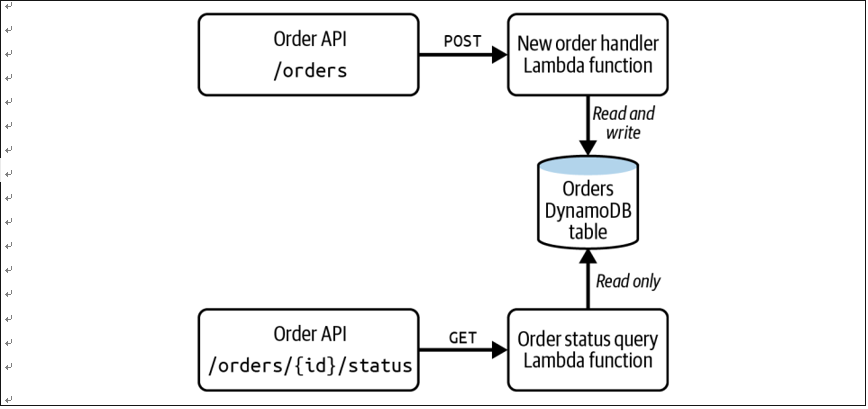
Figure 1-11 shows a simple serverless application that allows you to store orders and query the status of a given order via the POST /orders and GET /orders/{id}/ status endpoints, respectively, which are handled by the corresponding Lambda functions. The function that queries the Orders table to find the status performs a read operation. Since this function does not change the data in the table, it requires just the dynamodb:Query privilege. This idea of providing the minimum permissions required to complete a task is known as the principle of least privilege.
The principle of least privilege is a security best practice that grants only the permissions required to perform a task. As shown in Example 1-1, you define this as an IAM policy by limiting the permitted actions on specific resources. It is one of the most fun‐ damental security principles in AWS and should be part of the security thinking of every engineer. You will learn more about this topic in Chapter 4.
Figure 1-11. Serverless application showing two functions with different access privileges to the same data table
Granular permissions at the record level
The IAM policy in Example 1-1 showed how you configure access to read (query) data from the Orders table. Table 1-1 contains sample data of a few orders, where an order is split into three parts for better access and privacy: SOURCE, STATUS, and ADJUSTED.
Table 1-1. Sample Orders table with multiple item types
Per the principle of least privilege, the Lambda function that queries the status of an order should only be allowed to access that order’s STATUS record. Table 1-2 highlights the records that should be accessible to the function.
Table 1-2. STATUS records accessible to the status query function
To achieve this, you can use an IAM policy with a dynamodb:LeadingKeys condition and the policy details listed in Example 1-2.
Example 1-2. Policy to restrict read access to a specific type of item
{
“Version”: “2012-10-17”,
“Statement”: [
{
“Sid”: “AllowOrderStatus”,
“Effect”: “Allow”,
“Action”: [
“dynamodb:GetItem”,
“dynamodb:Query”
],
“Resource”: [
“arn:aws:dynamodb:…:table/Orders”
],
“Condition”: {
“ForAllValues:StringEquals”: {
“dynamodb:LeadingKeys”: [
“STATUS”
]
}
}
}
]
}
The conditional policy shown here works at a record level. DynamoDB also supports attribute-level conditions to fetch the values from only the permitted attributes of a record, for applications that require even more granular access control.
Policies like this one are common in AWS and applicable to several common services you will use to build your applications. Awareness and understanding of where and when to use them will immensely benefit you as a serverless engineer.
Iterative development empowers teams to develop and deliver products in small increments but in quick succession. As Eric Ries says in his book The Startup Way (Penguin), you start simple and scale fast. Your product constantly evolves with new features that benefit your customers and add business value.
Event-driven architecture (EDA), which we’ll explore in detail in Chapter 3, is at the heart of serverless development. In serverless, you compose your applications with loosely coupled services that interact via events, messages, and APIs. EDA principles enable you to build modular and extensible serverless applications.1 When you avoid hard dependencies between your services, it becomes easier to extend your applica‐ tions by adding new services that do not disrupt the functioning of the existing ones.
Multiskilled, Diverse Engineering Teams
Adopting new technology brings changes as well as challenges in an organization. When teams move to a new language, database, SaaS platform, browser technology, or cloud provider, changes in that area often require changes in others. For example, adopting a new programming language may call for modifications to the develop‐ ment, build, and deployment processes. Similarly, moving your applications to the cloud can create demand for many new processes and skills.
Influence of DevOps culture
The DevOps approach removes the barriers between development and operations, making it faster to develop new products and easier to maintain them. Adopting a DevOps model takes a software engineer who otherwise focuses on developing applications into performing operational tasks. You no longer work in a siloed soft‐ ware development cycle but are involved in its many phases, such as continuous integration and delivery (CI/CD), monitoring and observability, commissioning the cloud infrastructure, and securing applications, among other things.
A module is an independent and self-contained unit of software.
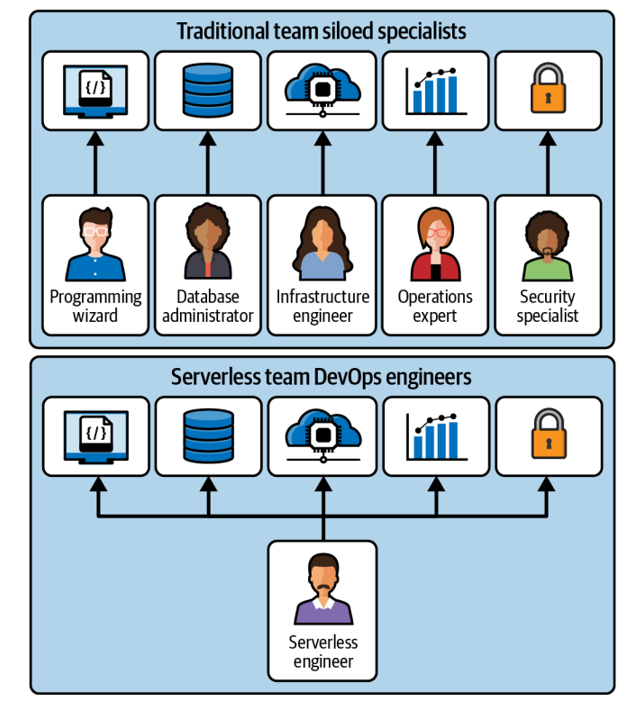
Adopting a serverless model takes you many steps further. Though it frees you from managing servers, you are now programming the business logic, composing your application using managed services, knitting them together with infrastructure as code (IaC), and operating them in the cloud. Just knowing how to write software is not enough. You have to protect your application from malicious users, make it available 24/7 to customers worldwide, and observe its operational characteristics to improve it continually. Becoming a successful serverless engineer thus requires devel‐ oping a whole new set of skills, and cultivating a DevOps mindset (see Figure 1-12).
Figure 1-12. Traditional siloed specialist engineers versus multiskilled serverless engineers
Consider the simple serverless application shown in Figure 1-8, where a Lambda function reads and writes to a DynamoDB table. Imagine that you are proficient in TypeScript and have chosen Node.js as your Lambda runtime environment. As you implement the function, it becomes your responsibility to code the interactions with DynamoDB. To be efficient, you learn NoSQL concepts, identify the partition key (PK) and sort key (SK) attributes as well as appropriate data access patterns to write your queries, etc. In addition, there may be data replication, TTL, caching, and other requirements. Security is also a concern, so you then learn about AWS IAM, how to create roles and policies, and, most importantly, the principle of least privilege. From being a programmer proficient in a particular language, your engineering role takes a 360-degree turn. As you evolve into a serverless engineer, you pick up many new skills and responsibilities.
As you saw in the previous section, your job requires having the ability to build the deployment pipeline for your application, understand service metrics, and proac‐ tively act on production incidents. You’re now a multiskilled engineer—and when most engineers in a team are multiskilled, it becomes a diverse engineering team capable of efficient end-to-end serverless delivery. For organizations where upskilling of engineers is required, Chapter 2 discusses in detail the ways to grow serverless talents.
The Parts of a Serverless Application and Its Ecosystem
An ecosystem is a geographic area where plants, animals, and other organisms, as well as weather and landscape, work together to form a bubble of life.
In nature, an ecosystem contains both living and nonliving parts, also known as factors. Every factor in an ecosystem depends on every other factor, either directly orindirectly. The Earth’s surface is a series of connected ecosystems.
The ecosystem analogy here is intentional. Serverless is too often imagined as an architecture diagram or a blueprint, but it is much more than FaaS and a simple framework. It has both technical and nontechnical elements associated with it. Ser‐ verless is a technology ecosystem!
As you learned earlier in this chapter, managed services form the bulk of a serverless application. However, they alone cannot bring an application alive—many other factors are involved. Figure 1-13 depicts some of the core elements that make up the serverless ecosystem.
Figure 1-13. Parts of the serverless technology ecosystem
They include:
The cloud platform
This is the enabler of the serverless ecosystem—AWS in our case. The cloud host‐ ing environment provides the required compute, storage, and network resources.
Managed cloud services
Managed services are the basic building blocks of serverless. You compose your applications by consuming services for computation, event transportation, mes‐ saging, data storage, and various other activities.
Architecture
This is the blueprint that depicts the purpose and behavior of your serverless application. Defining and agreeing on an architecture is one of the most impor‐ tant activities in serverless development.
Infrastructure definition
Infrastructure definition—also known as infrastructure as code (IaC) and expressed as a descriptive script—is like the circuit diagram of your application. It weaves everything together with the appropriate characteristics, dependencies, permissions, and access controls. IaC, when actioned on the cloud, holds the power to bring your serverless application alive or tear it down.
Development and test tools
The runtime environment of your FaaS dictates the programming language, libraries, plug-ins, testing frameworks, and several other developer aids. These tools may vary from one ecosystem to another, depending on the product domain and the preferences of the engineering teams.
Repository and pipelines
The repository is a versioned store for all your artifacts, and the pipelines per‐ form the actions that take your serverless application from a developer environ‐ ment all the way to its target customers, passing through various checkpoints along the way. The infrastructure definition plays a pivotal role in this process.
Observability tools
Observability tools and techniques act as a mirror to reflect the operational state of your application, offering deeper insights into how it performs against its intended purpose. A non-observable system cannot be sustained.
Best practices
To safeguard your serverless application against security threats and scaling demands and ensure it is both observable and resilient in the face of unexpected disruptions, you need well-architected principles and best practices acting as guardrails. The AWS Well-Architected Framework is an essential best practices guide; we’ll look at it later in this chapter.
Builders and stakeholders
The people who come up with the requirements for an application and the ones who design, build, and operate it in the cloud are also part of the ecosystem. In addition to all the tools and techniques, the role of humans in a serverless ecosystem is vital—they’re the ones responsible for making the right decisions and performing the necessary actions, similar to the role we all play in our environmental ecosystem!
As mentioned earlier in this chapter, although the term serverless first appeared in the industry in around 2012, it gained traction after the release of AWS Lambda in 2014. While the large numbers of people who jumped on the Lambda bandwagon elevated serverless to new heights, AWS already had a couple of fully managed serverless services serving customers at this point. Amazon SQS was released almost 10 years before AWS Lambda. Amazon S3, the much-loved and widely used object store in the cloud, was launched in 2006, way before the cloud reached the corners of the IT industry.
This early leap into the cloud with a futuristic vision, offering container services and fully managed serverless services, enabled Amazon to roll out new products faster than any other provider. Recognizing the potential, many early adopters swiftly realized their business ideas and launched their applications on AWS. Even though the cloud market is growing rapidly, AWS remains the top cloud services provider globally.
The Popularity of Serverless Services from AWS
Working closely with customers and monitoring industry trends has allowed AWS to quickly iterate ideas and launch several important serverless services in areas such as APIs, functions, data stores, data streaming, AI, machine learning, event transportation, workflow and orchestration, and more.
What’s in a Name?
When you look at the AWS service names, you’ll notice a mix of “Amazon” and “AWS” prefixes—for example, Amazon DynamoDB and AWS Step Functions. This confuses everyone, including employees at Amazon. Apparently, it’s not a random selection but a way to differentiate services based on their fundamental characteristics.
The most popular and relevant theory suggests that services with the Amazon prefix work on their own (standalone services), whereas the ones with the AWS prefix support other services (utility services) and are not intended to be used on their own. AWS Lambda, for example, is triggered by other services. However, as services evolve over time with new capabilities, you may find exceptions where this distinction no longer holds true.
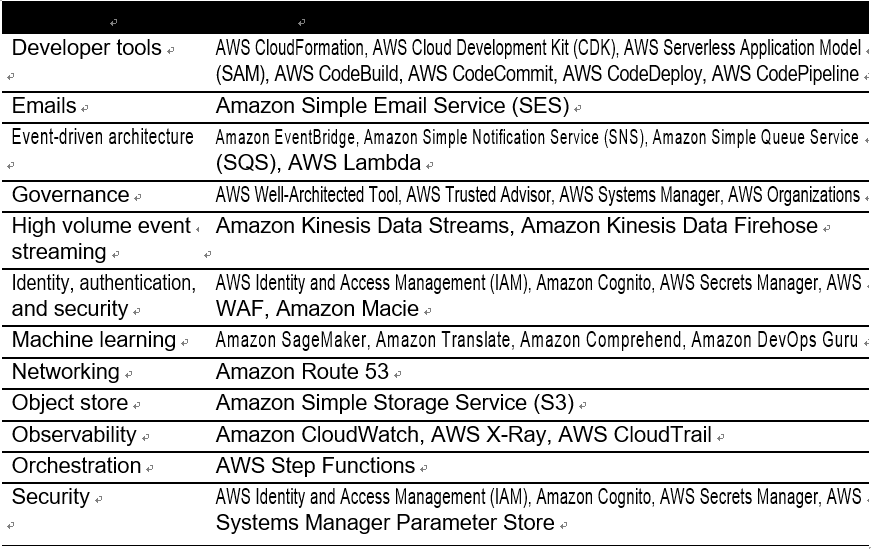
AWS is a comprehensive cloud platform offering over 200 services to build and operate both serverless and non-serverless workloads. Table 1-3 lists some of the most commonly used managed serverless services. You will see many of these services featured in our discussions throughout this book.
The AWS Well-Architected Framework is a collection of architectural best practices for designing, building, and operating secure, scalable, highly available, resilient, and cost-effective applications in the cloud. It consists of six pillars covering fundamental areas of a modern cloud system:
The Operational Excellence pillar provides design principles and best practices to devise organizational objectives to identify, prepare, operate, observe, and improve operating workloads in the cloud. Failure anticipation and mitigation plans, evolving applications in small but frequent increments, and continuous evaluation and improvements of the operational procedures are some of the core principles of this pillar.
The Security pillar focuses on identity and access management, protecting appli‐ cations at all layers, ensuring data privacy and control as well as traceability and auditing of all actions, and preparing for and responding to security events. It instills security thinking at all stages of development and is the responsibility of everyone involved.
An application deployed and operated in the cloud should be able to scale and function consistently as demand changes. The principles and practices of the
Reliability pillar include designing applications to work with service quotas and limits, preventing and mitigating failures, and identifying and recovering from failures, among other guidance.
The Performance Efficiency pillar is about the approach of selecting and the use of the right technology and resources to build and operate an efficient system. Monitoring and data metrics play an important role here in constantly reviewing and making trade-offs to maintain efficiency at all times.
The Cost Optimization pillar guides organizations to operate business applica‐ tions in the cloud in a way that delivers value and keeps costs low. The best practices focus on financial management, creating cloud cost awareness, using cost-effective resources and technologies such as serverless, and continuously analyzing and optimizing based on business demand.
The Sustainability pillar is the latest addition to the AWS Well-Architected Framework. It focuses on contributing to a sustainable environment by reducing energy consumption; architecting and operating applications that reduce the use of compute power, storage space, and network round trips; use of on-demand resources such as serverless services; and optimizing to the required level and not over.
Depending on the scale of your cloud operation and the company’s size, Amazon offers four technical support plans to suit your needs:
Developer
This is the entry-level support model, suitable for experimentation, building prototypes, or testing simple applications at the start of your serverless journey.
Business
As you move from the experimentation stage toward production deployments and operating business applications serving customers, this is the recommended support level. As well as other support features, it adds response time guarantees for production systems that are impaired or go down (<4 hours and <1 hour, respectively).
Enterprise on-ramp
The main difference between this one and the Enterprise plan is the response time guarantee when business-critical applications go down (<30 minutes, versus <15 minutes with the higher-level plan). The lower-level plans do not offer this guarantee.
Enterprise
If you’re part of a big organization with several teams developing and operating high-profile, mission-critical workloads, the Enterprise support plan will give you the most immediate care. In the event of an incident with your mission-critical applications, you get support within 15 minutes. This plan also comes with several additional benefits, including:
A dedicated Technical Account Manager (TAM) who acts as the first point of contact between your organization and AWS
Regular (typically monthly) meeting cadence with your TAM
Advice from AWS experts, such as solution architects specializing in your business domain, when building an application
Evaluation of your existing systems and recommendations based on AWS Well-Architected Framework best practices
Training and workshops to improve your internal AWS skills and develop‐ ment best practices
News about new product launches and feature releases
Opportunities to beta-test new products before they become generally available
Invitations to immersion days and face-to-face meetings with AWS product teams related to the technologies you work with
The number one guiding principle at Amazon is customer obsession: “Leaders start with the customer and work back‐ wards. They work vigorously to earn and keep customer trust. Although leaders pay attention to competitors, they obsess over customers.”
During the early 2000s, I (Sheen) was involved in building distributed applications that mainly communicated via service buses and web services—a typical service-oriented architecture (SOA). It was during this time that I first came across the term “the cloud,” which was making a few headlines in the tech industry. A few years later, I received instructions from upper management to study this new technology and report on certain key features. The early cloud offering that I was asked to explore was none other than Amazon Web Services.
My quest to get closer to the cloud started there, but it took me another few years to fully appreciate and understand the ground-shifting effect it was having in the industry. Like the butterfly effect, it was fascinating to consider how past events had brought us to the present.
The butterfly effect is a term used to refer to the concept that a small change in the state of a complex system can have nonlinear impacts on the state of that system at a later point. The most common example cited is that of a butterfly flapping its wings somewhere in the world acting as a trigger to cause a typhoon elsewhere.
From Mainframe Computing to the Modern Cloud
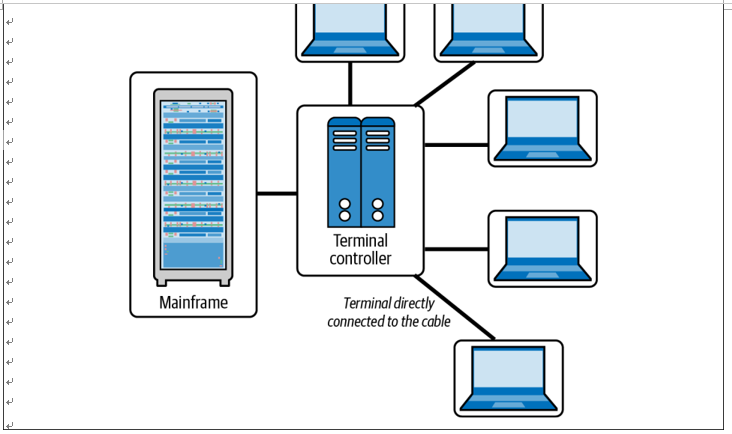
During the mid-1900s, mainframe computers became popular due to their vast com‐ puting power. Though massive, clunky, highly expensive, and laborious to maintain, they were the only resources available to run complex business and scientific tasks. Only a lucky few organizations and educational institutions could afford them, and they ran jobs in batch mode to make the best use of the costly systems. The concept of time-sharing was introduced to schedule and share the compute resources to run programs for multiple teams (see Figure 1-1). This distribution of the costs and resources made computing more affordable to different groups, in a way similar to the on-demand resource usage and pay-per-use computing models of the modern cloud.
Figure 1-1. Mainframe computer time-sharing (source: adapted from an image in Guide to Operating Systems by Greg Tomsho [Cengage])
Early mainframes were independent and could not communicate with one another. The idea of an Intergalactic Computer Networkor Galactic Network to interconnect remote computers and share data was introduced by computer scientist J.C.R. Lick‐ lider, fondly known as Lick, in the early 1960s. The Advanced Research Projects Agency (ARPA) of the United States Department of Defense pioneered the work, which was realized in the Advanced Research Projects Agency Network (ARPANET). This was one of the early network developments that used the TCP/IP protocol, one of the main building blocks of the internet. This progress in networking was a huge step forward.
The beginning of virtualization
The 1970s saw another core technology of the modern cloud taking shape. In 1972, the release of the Virtual Machine Operating System by IBM allowed it to host multiple operating environments within a single mainframe. Building on the early time-sharing and networking concepts, virtualization filled in the other main piece of the cloud puzzle. The speed of technology iterations of the 1990s brought those ideas to realization and took us closer to the modern cloud. Virtual private networks (VPNs) and virtual machines (VMs) soon became commodities.
The term cloud computing originated in the mid to late 1990s. Some attribute it to computer giant Compaq Corporation, which mentioned it in an internal report in 1996. Others credit Professor Ramnath Chellappa and his lecture at INFORMS 1997 on an “emerging paradigm for computing.” Regardless, with the speed at which technology was evolving, the computer industry was already on a trajectory for massive innovation and growth.
The first glimpse of Amazon Web Services
As virtualization technology matured, many organizations built capabilities to auto‐ matically or programmatically provision VMs for their employees and to run busi‐ ness applications for their customers. An ecommerce company that made good use of these capabilities to support its operations was Amazon.com.
During early 2000, engineers at Amazon were exploring how their infrastructure could efficiently scale up to meet the increasing customer demand. As part of that process, they decoupled common infrastructure from applications and abstracted it as a service so that multiple teams could use it. This was the start of the concept known today as infrastructure as a service (IaaS). In the summer of 2006, the com‐ pany launched Amazon Elastic Compute Cloud (EC2) to offer virtual machines as a service in the cloud for everyone. That marked the humble beginning of today’s mammoth Amazon Web Services, popularly known as AWS!
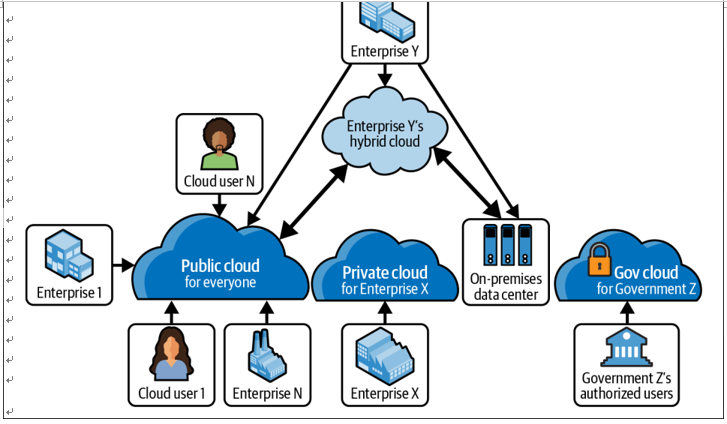
As cloud services gained momentum thanks to the efforts of companies like Amazon, Microsoft, Google, Alibaba, IBM, and others, they began to address the needs of different business segments. Different access models and usage patterns started to emerge (see Figure 1-2).
Figure 1-2. Figurative comparison of different cloud environments
These are the main variants today:
Public cloud
The cloud service that the majority of us access for work and personal use is the public cloud, where the services are accessed over the public internet. Though cloud providers use shared resources in their data centers, each user’s activities are isolated with strict security boundaries. This is commonly known as a multitenant environment.
Private cloud
In general, a private cloud is a corporate cloud where a single organization has access to the infrastructure and the services hosted there. It is a single-tenant environment. A variant of the private cloud is the government cloud (for example, AWS GovCloud), where the infrastructure and services are specifically for a par‐ ticular government and its organizations. This is a highly secure and controlled environment operated by the respective country’s citizens.
Hybrid cloud
A hybrid cloud uses both public and private cloud or on-premises infrastructure and services. Maintaining these environments requires clear boundaries on secu‐ rity and data sharing.
Enterprises that prefer running their workloads and consuming services from multiple public cloud providers operate in what is called a multicloud environment. We will discuss this further in the next chapter.
The Influence of Running Everything as a Service
The idea of offering something “as a service” is not new or specific to software. Public libraries are a great example of providing information and knowledge as a ser‐ vice: we borrow, read, and return books. Leasing physical computers for business is another example, which eliminates spending capital on purchasing and maintaining resources. Instead, we consume them as a service for an affordable price. This also allows us the flexibility to use the service only when needed—virtualization changes it from a physical commodity to a virtual one.
In technology, one opportunity leads to several opportunities, and one idea leads to many. From bare VMs, the possibilities spread to network infrastructure, databases, applications, artificial intelligence (AI), and even simple single-purpose functions. Within a short span, the idea of something as a service advanced to a point where we can now offer almost anything and everything as a service!