

Pay-per-Use – Introduction to Serverless on AWS
Pay-per-Use
Pay-per-use is the main characteristic that everyone associates with serverless. It mainly originated from the early days of serverless, when it was equated with FaaS: you pay for each function invocation. That interpretation is valid for ephemeral services such as AWS Lambda; however, if your application handles data, you may have a business requirement to store the data for a longer period and for it to be accessible during that time. Fully managed services such as Amazon DynamoDB and Amazon S3 are examples of services used for long-term data storage. In such cases, there is a cost associated with the volume of data your applications store every month, often measured in gibibytes (GiB). Remember, this is still pay-per-use based on your data volume, and you are not charged for an entire disk drive or storage array.
Figure 1-8 shows a simple serverless application where a Lambda function operates on the data stored in a DynamoDB table. While you pay for the Lambda function based on the number of invocations and memory consumption, for DynamoDB, in addition to the pay-per-use cost involved with its API invocations for reading and writing data, you also pay for the space consumed for storing the data. In Chapter 9, you will see all the cost elements related to AWS Lambda and DynamoDB in detail.
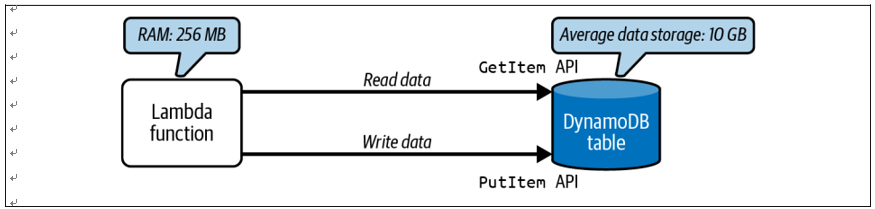
Figure 1-8. A simple serverless application, illustrating pay-per-use and data storage cost elements
Autoscaling and Scale to Zero
One of the primary characteristics of a fully managed service is the ability to scale up and down based on demand, without manual intervention. The term scale to zero is unique to serverless. Take, for example, a Lambda function. AWS Lambda manages the infrastructure provisioning to run the function. When the function ends and is no longer in use, after a certain period of inactivity the service reclaims the resources used to run it, scaling the number of execution environments back to zero.
AWS Lambda Execution Environments
When a Lambda function is invoked, the AWS Lambda service runs the function code inside an execution environment. The execution environment is run on a hardware-virtualized virtual machine (MicroVM) known as Firecracker. The execu‐ tion environment provides a secure and isolated runtime environment for function execution. It consists of the function code, any extensions, temporary local filesystem space, and language runtime.
One execution environment is associated with one Lambda function and never shared across functions.
Conversely, when there is a high volume of requests for a Lambda function, AWS automatically scales up by provisioning the infrastructure to run as many concurrent instances of the execution environment as needed to meet the demand. This is often referred to as infinite scaling, though the total capacity is actually dependent on your account’s concurrency limit.
With AWS Lambda, you can opt to keep a certain number of function containers “warm” in a ready state by setting a function’s provisioned concurrency value.
Both scaling behaviors make serverless ideal for many types of applications.
Lambda Function Timeout
At the time of writing, a Lambda function can run for a maximum execution time of 15 minutes. This is commonly referred to as the timeout period. While developing a Lambda function, you can set the timeout to any value up to 15 minutes. You set this value based on how long the function requires to complete the execution of its logic, and expect it to finish before its timeout. If the function is still executing when it reaches its set timeout, the AWS Lambda service terminates it.