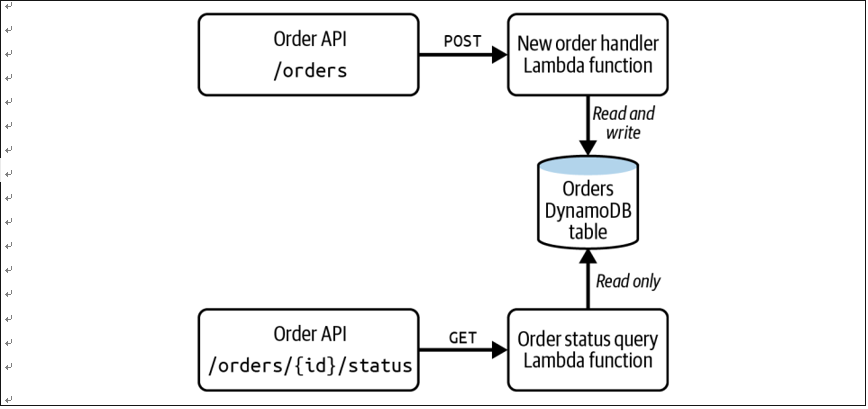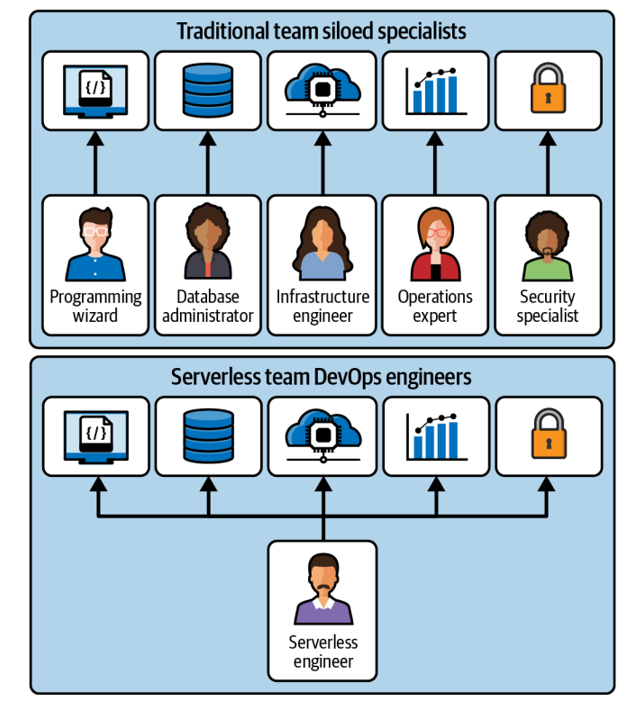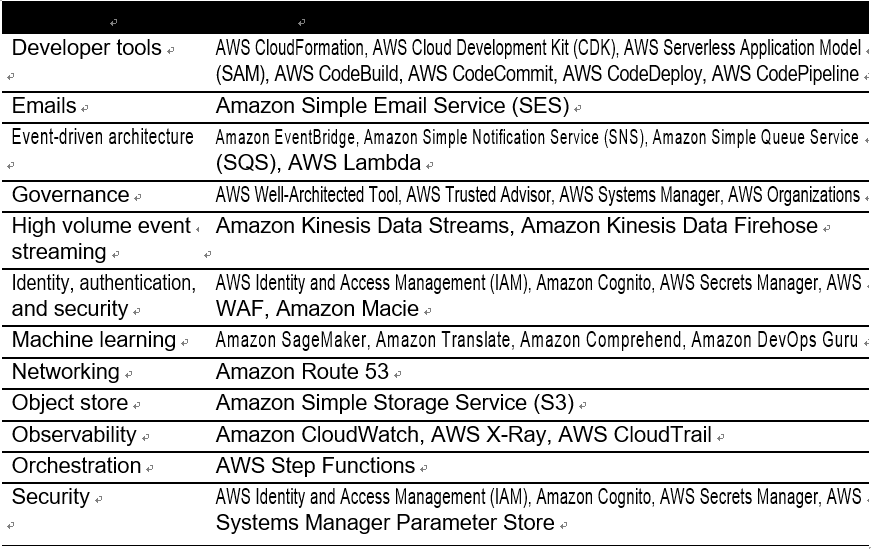

Threat modeling with MITRE ATT&CK – Keeping Up with Evolving AWS Security Best Practices and Threat Landscape
Threat modeling with MITRE ATT&CK
The MITRE ATT&CK framework has emerged as an interesting tool for organizations using AWS to understand, anticipate, and counteract cyber threats. This globally recognized framework offers a comprehensive matrix of tactics and techniques that are commonly employed by cyber adversaries. The MITRE ATT&CK for Cloud matrix, specifically, is tailored to address cloud environments. It provides insights into potential cloud-specific threats and vulnerabilities, which are particularly useful for AWS users.
Incorporating the MITRE ATT&CK framework into AWS security practices offers numerous benefits as it provides a structured methodology for understanding and anticipating potential threats within your AWS landscape. Here are its key integrations:
- Mapping to AWS services: By aligning the ATT&CK framework with AWS services, organizations can gain detailed insights into potential attack vectors. This involves understanding how specific ATT&CK tactics and techniques can be applied to or mitigated by AWS services, such as EC2, S3, or IAM.
- Utilization in security assessments: Incorporating the framework into security assessments allows for a more thorough evaluation of AWS environments. It helps in identifying vulnerabilities that could be exploited through known attack methodologies, thus enabling a more targeted approach to securing cloud assets. For instance, organizations can use the framework to simulate attack scenarios, such as a credential access attack, where an attacker might attempt to obtain AWS access keys through phishing or other methods.
- Enhancing incident response: The framework can significantly improve incident response strategies. By mapping ongoing attacks to the ATT&CK matrix, incident response teams can more quickly understand the attacker’s Tactics, Techniques, and Procedures (TTPs), leading to faster and more effective containment and remediation.
- Feeding continuous monitoring: The framework aids in the development of continuous monitoring strategies that are more aligned with the evolving threat landscape. It allows security teams to proactively look for indicators of attack tactics and techniques, enabling early detection of potential threats.
- Developing customized threat models: Creating threat models based on ATT&CK scenarios tailored to AWS can significantly enhance defense strategies. For example, building a model around the exfiltration techniques can help in preparing defenses against potential data breaches from S3 buckets.
- Developing red team exercises: Conducting red team exercises using ATT&CK-based scenarios provides a realistic test of AWS defenses. For example, simulating an attack where a red team uses lateral movement techniques to move between EC2 instances can test the effectiveness of network segmentation and access controls.
Building upon our discussion of MITRE ATT&CK and how to handle emerging threats in general, next, we will explore the wealth of resources available for continuous learning in AWS security.